原文:Building Production-Ready Agentic Systems: Lessons from Shopify Sidekick
作者:Andrew McNamara
本文改编自 Andrew McNamara、Ben Lafferty 和 Michael Garner 在 ICML 2025 上的演讲:构建生产就绪的智能体系统:架构、基于大语言模型的评估与 GRPO 训练。
在 Shopify,我们一直在打造 Sidekick,一个由 AI 驱动的助手,帮助商家通过自然语言交互来管理他们的店铺。从分析客户群体到填写商品表单,再到驾驭复杂的后台界面,Sidekick 已经从一个简单的工具调用系统,演变成了一个复杂的 AI 智能体 (AI Agent) 平台。一路走来,我们在架构设计、评估方法和训练技术上学到了宝贵的经验,希望能与更广泛的 AI 工程社区分享。
Sidekick 架构的演进之路
Sidekick 的核心是围绕着 Anthropic 公司所说的“智能体循环” (agentic loop) 构建的——这是一个持续的循环:人类提供输入,大语言模型 (LLM) 处理输入并决定要执行的动作,这些动作在环境中被执行,系统收集反馈,然后循环继续,直到任务完成。
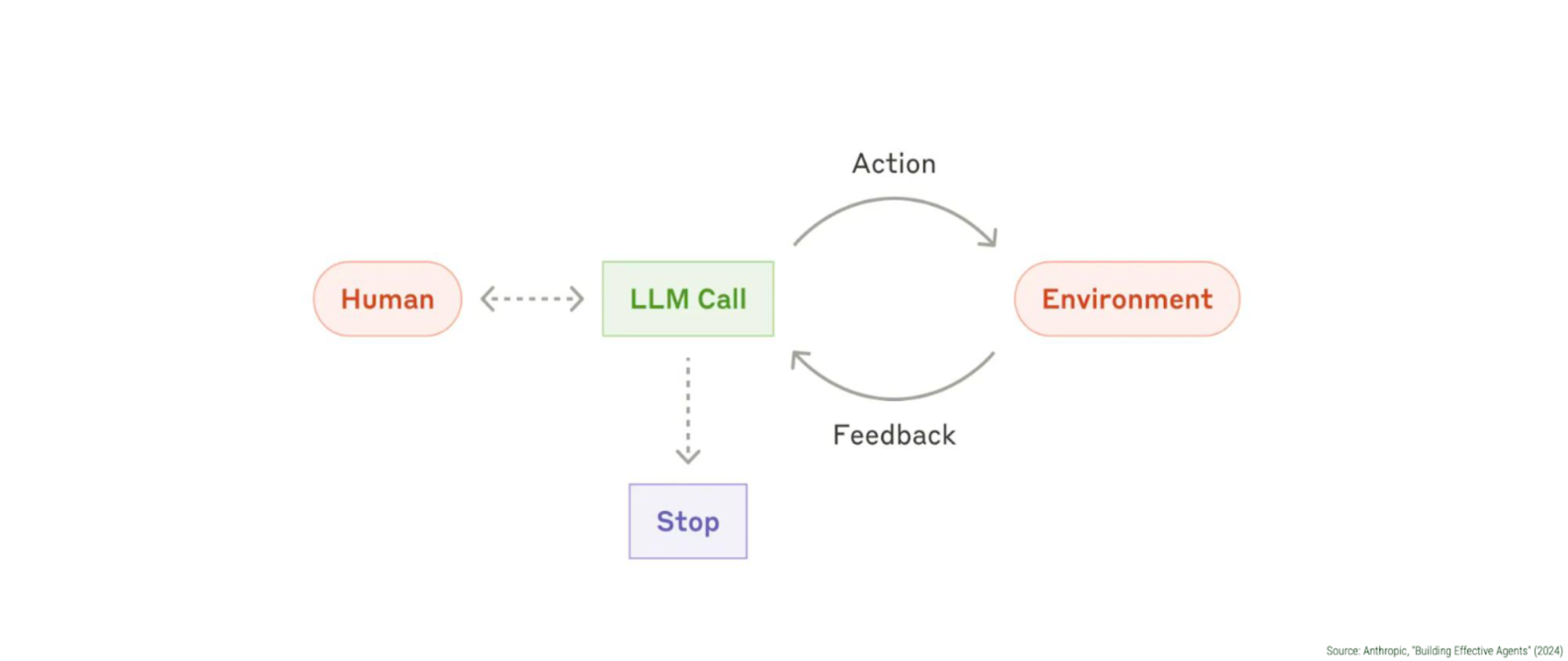
在实践中,这意味着 Sidekick 可以处理像“我有哪些客户来自多伦多?”这样的请求,它会自动查询客户数据,应用合适的筛选条件,并呈现结果。或者,当商家需要帮助撰写 SEO 描述时,Sidekick 能够识别相关商品,理解上下文,并直接在商品表单中填入优化过的内容。
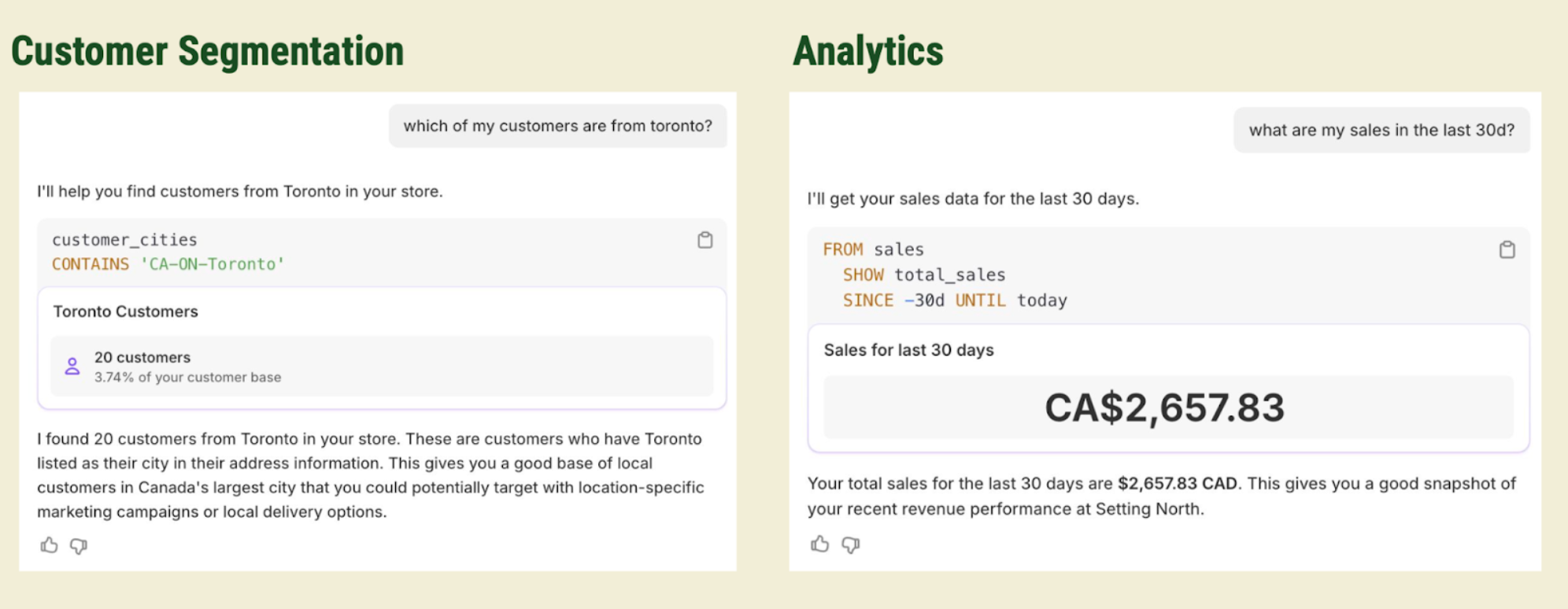
工具复杂性难题
随着我们不断扩展 Sidekick 的功能,我们很快就遇到了一个许多构建智能体系统的团队都会遇到的扩展性挑战。我们的工具库从最初几个定义明确的函数,增长到了几十个专业化的功能:

- 0-20 个工具:边界清晰,易于调试,行为直接。
- 20-50 个工具:边界开始模糊,工具之间的组合开始导致意想不到的结果。
- 50+ 个工具:完成同一任务有多种方式,系统变得难以理解和推理。
这种增长导致了我们称之为“千条指令之死” (Death by a Thousand Instructions) 的问题——我们的系统提示词变成了一堆杂乱无章的特殊情况、相互矛盾的指南和边缘案例处理的大杂烩,这不仅拖慢了系统速度,还让维护变得几乎不可能。
“即时指令”:应对规模化的解决方案
我们的突破来自于实现了“即时指令” (Just-in-Time Instructions, JIT)。我们不再把所有的指南都塞进系统提示词里,而是在工具数据返回的同时,附上相关的指令,只在需要它们的时候才提供。我们的目标是,在每一种情况下,都为大语言模型打造一个不多不少、恰到好处的上下文。
实践中如何运作
下图下方是提供给大语言模型的指令:
下图上方是大语言模型根据收到的指令做出的响应:

这种方法带来了三个关键好处:
- 局部化指导:指令只在相关时出现,让核心系统提示词专注于最基本的智能体行为。
- 缓存效率:我们可以动态调整指令,而不会破坏大语言模型的提示词缓存。
- 模块化:可以根据测试标志 (beta flags)、模型版本或页面上下文,提供不同的指令。
效果立竿见影——我们的系统变得更易于维护,同时所有性能指标都得到了提升。
构建稳健的大语言模型评估系统
部署智能体系统最大的挑战之一就是评估。传统的软件测试方法在处理大语言模型输出的概率性,以及多步骤智能体行为的复杂性时,显得力不从心。

如今,太多人只是在对他们的大语言模型系统进行“凭感觉测试” (vibe testing),并认为这就足够了;然而事实并非如此。“凭感觉测试”,或者创建一个“感觉流大语言模型裁判”让它“给这个打个 0-10 分”,是行不通的。评估必须有原则、有统计上的严谨性,否则你发布产品时所怀揣的只是一种虚假的安全感。
用“基准真相集”取代“黄金数据集”
我们放弃了精心策划的“黄金”数据集,转而采用能反映真实生产环境数据分布的“基准真相集” (Ground Truth Sets, GTX)。我们不再试图预测所有可能的交互(这通常是产品规格文档想做的事),而是从真实商家的对话中抽样,并根据我们在实践中观察到的情况来创建评估标准。

这个过程包括:
- 人工评估:让至少三位产品专家根据多个标准为对话打标签。
- 统计验证:使用科恩系数 (Cohen's Kappa)、肯德尔等级相关系数 (Kendall Tau) 和皮尔逊相关系数 (Pearson correlation) 来衡量标注者之间的一致性。
- 设定基准:将人类评估员之间的一致性水平,视为我们的大语言模型裁判所能达到的理论上限。

“大语言模型作为裁判”并与人类对齐
我们为 Sidekick 性能的不同方面开发了专门的大语言模型裁判,但关键的洞见是,要将这些裁判与人类的判断进行校准。通过迭代优化提示词,我们将裁判的性能从几乎和随机差不多(科恩系数为 0.02),提升到接近人类的水平(0.61,而人类基准为 0.69)。我们的理念是,一旦我们的大语言模型裁判与人类评估员高度相关,我们就会尝试在基准真相集里随机地用裁判替换掉某个评估员。当我们很难分辨出评估组里是混入了一个人还是一个裁判时,我们就知道我们拥有了一个值得信赖的大语言模型裁判。
使用“用户模拟”进行全面测试
为了在部署到生产环境前测试候选的系统变更,我们构建了一个由大语言模型驱动的商家模拟器。它能捕捉真实对话的“精髓”或目标,并在新的候选系统上重放这些对话。这使我们能够对许多不同的候选系统进行模拟,并选择表现最好的一个。